GraphQL vs REST: What I’ve learned so far
Two years ago, I was a month into my Software Engineering bootcamp learning everything I could about the joys of coding and the inner workings of APIs. I had been taught using RESTful APIs and all seemed straightforward as I created the apps required for my program and a year later was able to get my first internship. Then I got my first job at Echobind right after the internship and was introduced to GraphQL as an alternative to REST.
What is GraphQL?
GraphQL is a database query language that allows us to access and manipulate data from one source rather than needing numerous routes and the various CRUD operations. Working with it honestly feels like I’m trying to talk to a ghost who has the shape of the database but definitely is not the actual database itself. Thankfully the ghost will tell you about itself thanks to GraphQL’s self-documentation, assuming the schema has been effectively named.
GraphQL has a schema that helps us know what the data looks like, and what we can expect to receive in our requests to the API. The most important pieces of working with GraphQL that you need to know are types, queries, mutations, and resolvers. Types define the schema as an object, they can be made up of fields of scalar types: ID, String, Int, Float, and Boolean.
ytype Person { id: ID! # the ! means it's a required/non-nullable field name: String age: Int married: Boolean pets: [Animal] } type Animal { name: String species: String }
Fields can also be made of lists, objects, enums, and interfaces. You can also use lists like the [Animal] on Pets which will know to expect a nested query, in this case, an array of that defined type.
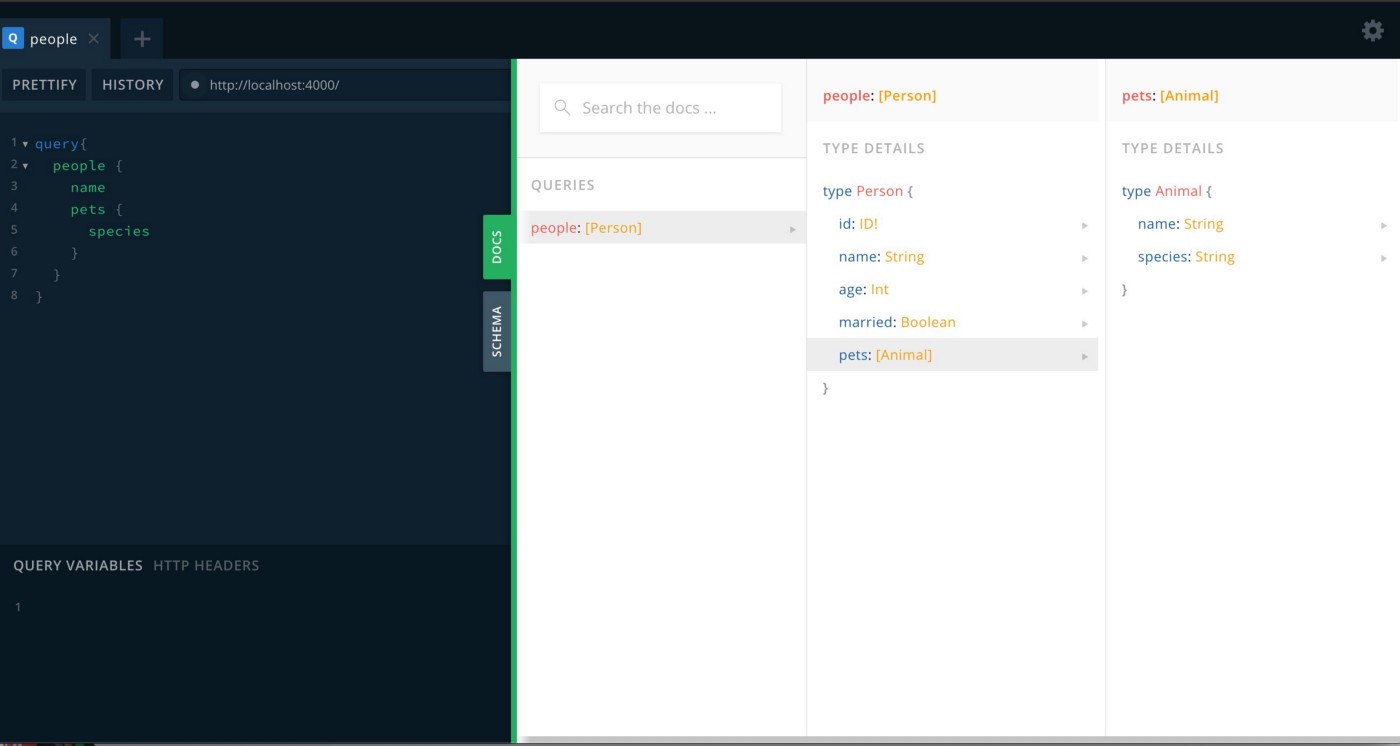
Queries are pretty straightforward as a means to read the aforementioned data. If you want to change the data in any way you must use a mutation. Mutations can be customized to return data in a specific way using resolvers.
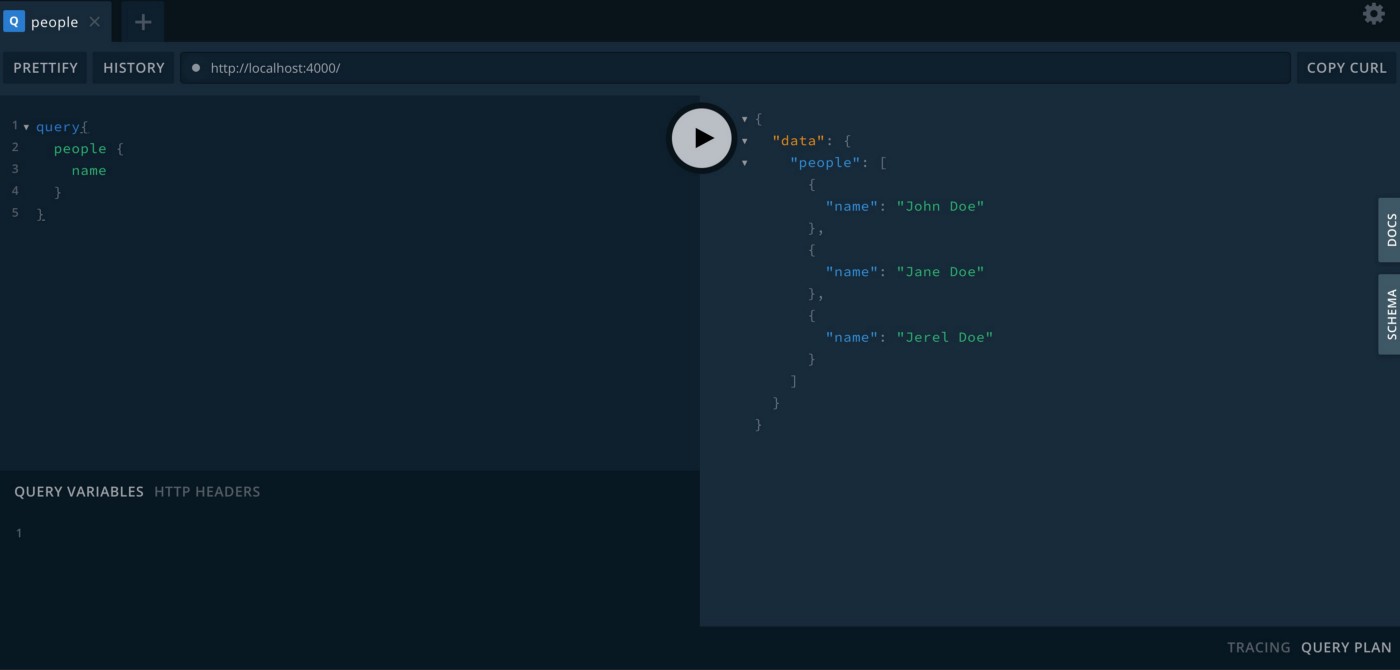
All of this sounds all well and good, or maybe like gibberish. It matters how we query and manipulate data when most are probably already familiar with RESTful APIs as I highlighted earlier.
GraphQL vs REST
GraphQL vs REST is like the current options for a grocery shopping experience: ordering online vs physically going to a store.

Your query is your shopping cart: you’re hoping to fill it with all of the data pieces that you need to complete your meal planning. Let’s imagine we want to plan out breakfast with something simple with eggs and coffee.
When you go to the REST grocery store, you grab a query cart and head in. Unfortunately, the query cart can really only be used for one of the items on the list at a time unless the grocery store thought to put related things together.
The various aisles in the REST grocery store can be considered routes, each dedicated to a specific resource and may contain a few other resources if someone thought that they are related to a given resource. If we want to get our coffee in an actual grocery store, we will likely find it in a drink aisle that contains everything. Depending on how the aisles are organized, you’ll find a number of other items that may fit into that category but ultimately were not what you were looking for. The drink aisle will include juice, powder, tea, concentrate, flavor mix-ins, and more; when all we were looking for was coffee. Not to mention all of the data about each of these options will also be given to us on the price tag/packaging.

What it feels like to query REST apis.
When we query a RESTful API, we will get all of the information about that specific resource, even if we didn’t ask for/need it. We may have just needed the name of the item but we will get that as well as the sale price, price per pound, weight, id, and other details that may be useful for something but not what we needed.
Compared to shopping online at the GraphQL mega retailer that offers everything but the moon all from one spot. In one trip to a website, I could request exactly what I wanted without going down multiple aisles and seeing a lot of extraneous details about the objects I’m looking for. Usually just see the name and price until I actually select the specific item.
This analogy kind of falls apart once we get to mutations. If shopping at the grocery store is our query, then mutations would be converting the eggs into an actual meal. Like some futuristic kitchen tool out of a science fiction setting, GraphQL allows us to do almost everything and anything to the eggs in one mutation through a POST request. On the other hand, REST expects us to use each individual route and supply whether it is a POST, PUT, or DELETE. Almost as if we had to use a specialized, As Seen On TV tool for whatever specific egg preparation we wanted.
What next?
It’s been fascinating to learn about and reflect on the differences between REST and GraphQL. Personally, I still appreciate what REST apis do when I have no idea all of the information that can be included on the first go or potentially just need the kitchen sink of that information. Having multiple routes that are specific to resources is also good for navigating errors in a potentially more straightforward way than what may occur with GraphQL.
GraphQL is great for when I know I need specific pieces of information and want to reduce the unnecessary data being pulled in. The self-documenting aspect of GraphQL makes that effort even easier assuming the schema types have been well named or has descriptions attached. This feature is made even easier to use with tools like GraphiQL and GraphQL Playground (which is included in Apollo Server). GraphQL Playground is really great because it let us explore the schema and understand the necessary parameters before we start querying the data.
I hope my analogies made the abstract a little more concrete and that you get the opportunity to explore these tools for your own curiosity and needs as they arise. May your future queries return your breakfast quickly and to order!



